Разделение данных на обучающую и тестовую выборки (сплит) является фундаментальной процедурой в машинном обучении. Рассмотрим ключевые причины применения этой методики.
Содержание
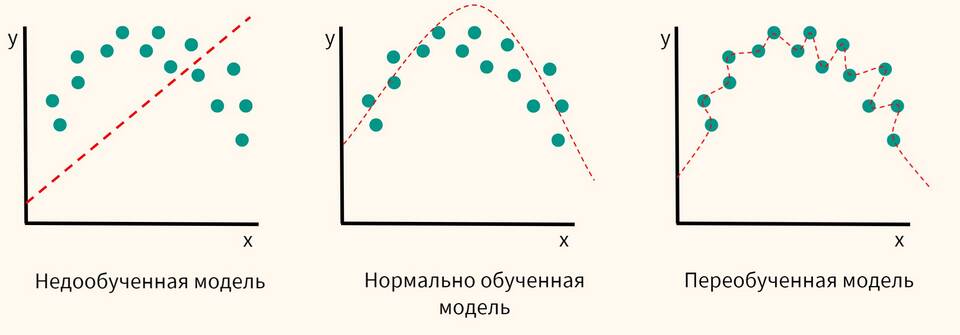
Оценка качества модели
Основные цели разделения данных:
- Тестирование модели на независимых данных
- Проверка способности к обобщению
- Предотвращение переобучения
- Оценка реальной производительности алгоритма
Виды сплитов
Основные методы разделения:
- Простое разделение (train-test split)
- Кросс-валидация (K-Fold, Stratified)
- Временное разделение для временных рядов
- Групповое разделение для коррелированных данных
Сравнение методов сплита
| Метод | Применение | Размер тестовой выборки |
| Train-Test | Быстрая оценка | 20-30% |
| K-Fold | Точная оценка | 1/K частей |
| Stratified | Несбалансированные данные | Зависит от распределения |
Практические аспекты
Правила эффективного разделения:
- Сохранение распределения признаков
- Предотвращение утечки данных
- Учет временных зависимостей
- Сохранение баланса классов
Типичные ошибки
Чего следует избегать:
- Разделение после предобработки (утечка данных)
- Игнорирование стратификации
- Случайное разделение временных рядов
- Недостаточный размер тестовой выборки
Правильное разделение данных - критически важный этап создания надежных моделей машинного обучения, позволяющий объективно оценить их производительность в реальных условиях.